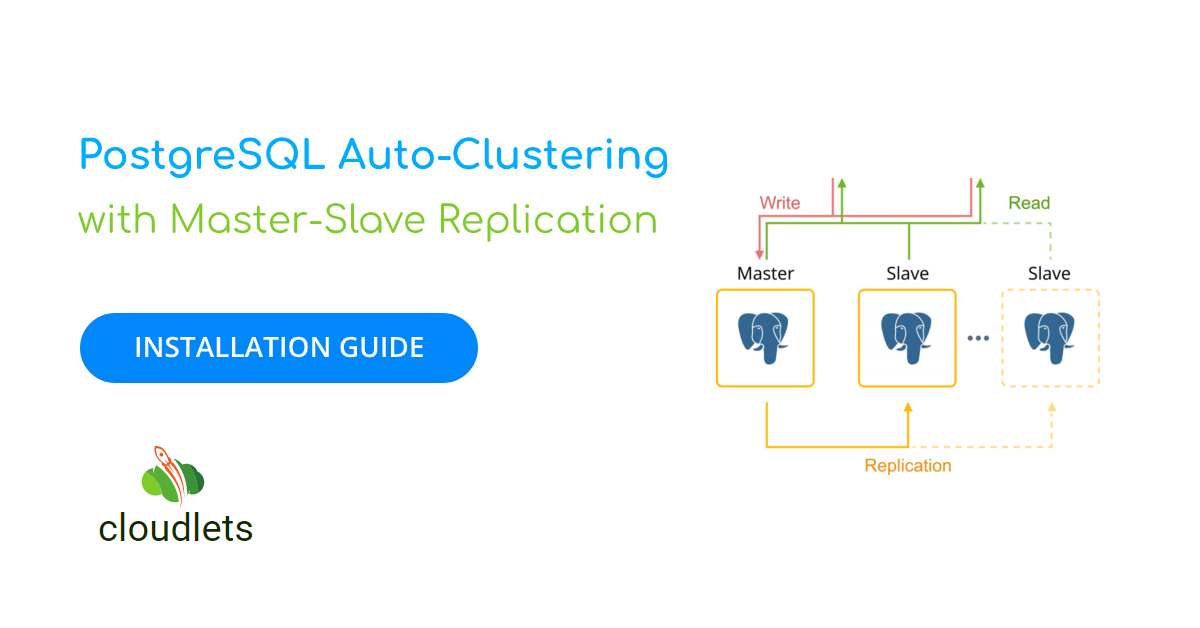
Storing data in the only one place is quite risky in case of a system failure. The best solution here will be ensuring high availability and maintain your data on multiple synchronized servers.
Data replication from one database to another allows to alleviate system failures, improve productivity, run backup services, and analyze data with no performance loss.
Cloudlets.com.au provides PostgreSQL with master-slave asynchronous replication based on the certified templates. It deploys two database master-slave containers:
- The primary (master) server runs an active instance of the database and accepts read-write operations
- The standby (slave) server runs a copy of the active database and handles read-only operations.
In case of fail the primary database (due to container failure or database corruption), the slave server has to be promoted to the master retaining the writes to ensure database availability.

This cluster topology contains database containers with predefined vertical scaling from 2 reserved to 32 dynamic cloudlets (up to 4 GiB of RAM and 12.8 GHz of CPU) allocated dynamically based on the load. It is also possible to customize resource allocation limit.
PostgreSQL Cluster can be easily installed automatically:
- From a Marketplace in 1 click
- Via embedded Auto-Clustering feature at the Dashboard
1 Click PostgreSQL Cluster Installation via Marketplace
Log in to the dashboard at https://app.cloudlets.com.au/. Open the Marketplace and choose the PostgreSQL Master-Slave Cluster for 1 click installation.
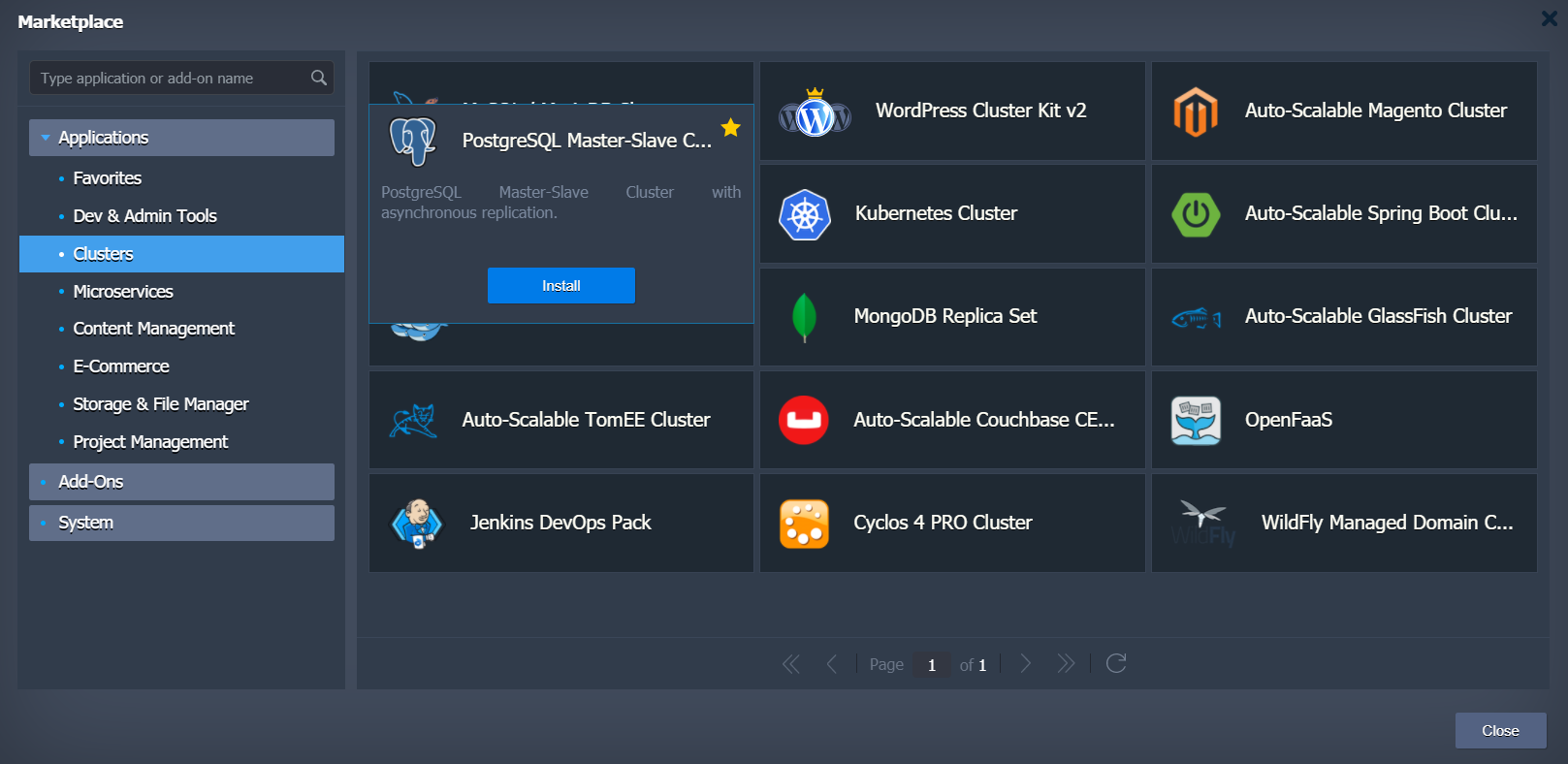
If required change the database Version and Environment name in the installation window.
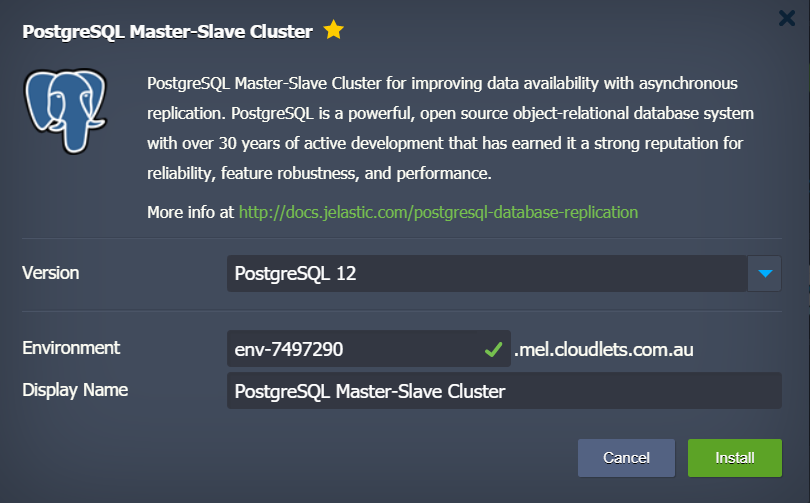
PostgreSQL Auto-Clustering Mode
You can also enable auto-clustering via a specially designed switch in a single click. To do this, open the dashboard, then choose the existing environment or create a new one, pick the software stack(e.g. PostgreSQL 12.3) and slide the Auto-Clustering switch to the ON position.
PostgreSQL Cluster Topology
Database cluster topology obtained upon both deployments looks like as follows:

When your PostgreSQL database cluster is deployed, you’ll see a confirmation message with master node URL and database access credentials (this info will be also duplicated via email).
How to Test PostgreSQL Database Replication
To ensure that data is replicated properly, let's create a new database instance in the master container and check its presence inside the slave.
Creating New Database
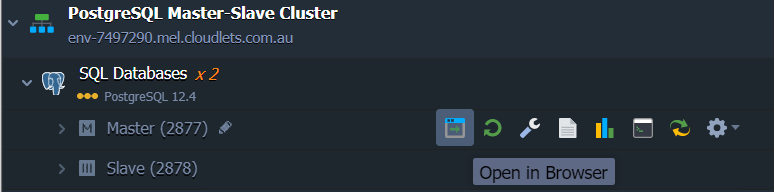
1. Click Open in Browser next to the PostgreSQL Master node to launch the phpPgAdmin web interface.
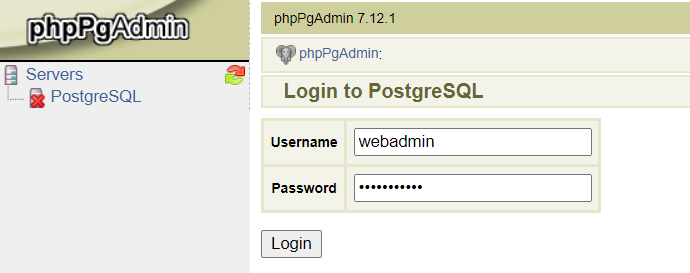
2. Click PostgreSQL and log in with credentials (you’ve received after the cluster installation).
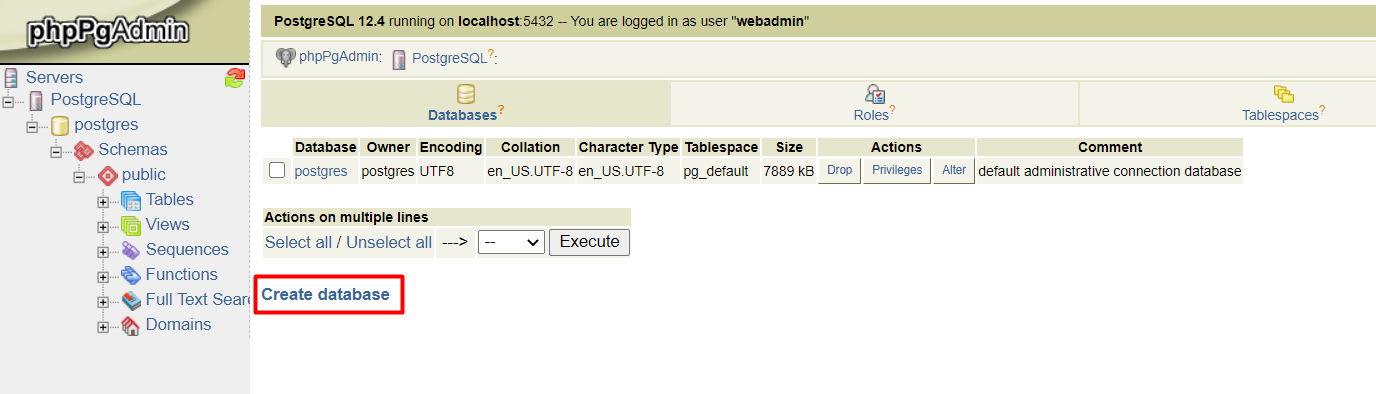
3. Click Create database.
4. Fill in the Name, click Create.
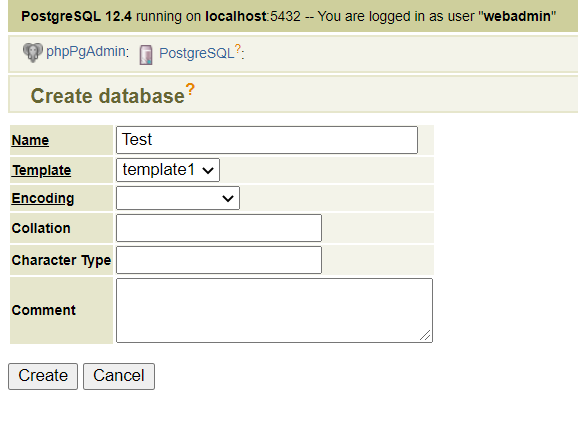
After the database is created in the master node, let’s check the replicated data within the slave node.
Check the Replication
Now we'll check whether data replication from the master to the slave database node works as intended.
1. Click Open in Browser next to the PostgreSQL Slave node to launch the phpPgAdmin web interface.
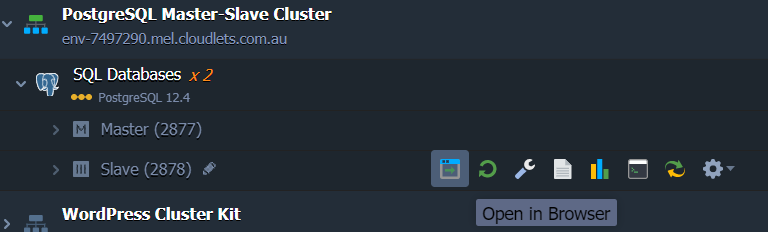
2. Access admin interface with the same username and password that you’ve used to access the master node.
After logging in, you'll see the replicated database (Test, in our case).
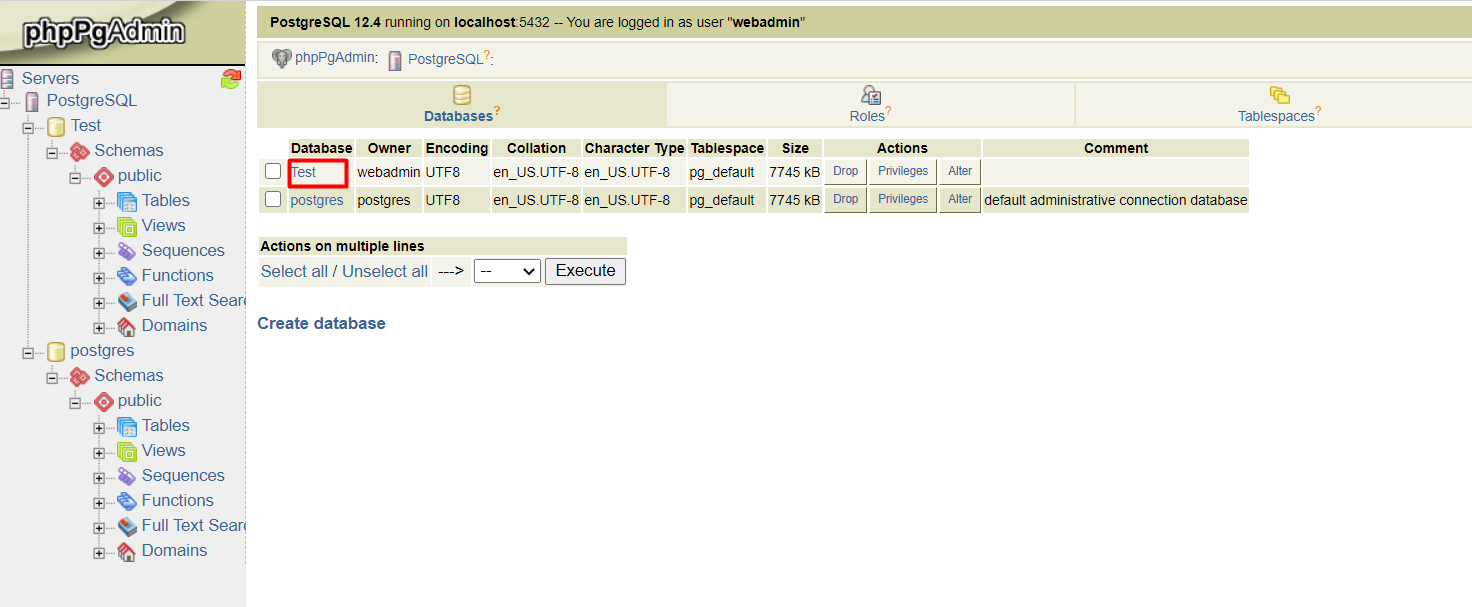
That’s all - now your PostgreSQL environment with master-slave asynchronous replication is up and ready for data processing.
As a next step, you can connect this PostgreSQL replicated database to your project.
Test it now and check how to handle multiple copies of data within replicated PostgreSQL databases without any manual configs - just register for free at https://app.cloudlets.com.au/